高吞吐量的分布式订阅消息系统
1.官网
http://kafka.apache.org/

2.官网的介绍

3.结构
这个是版本1.0之后的版本。
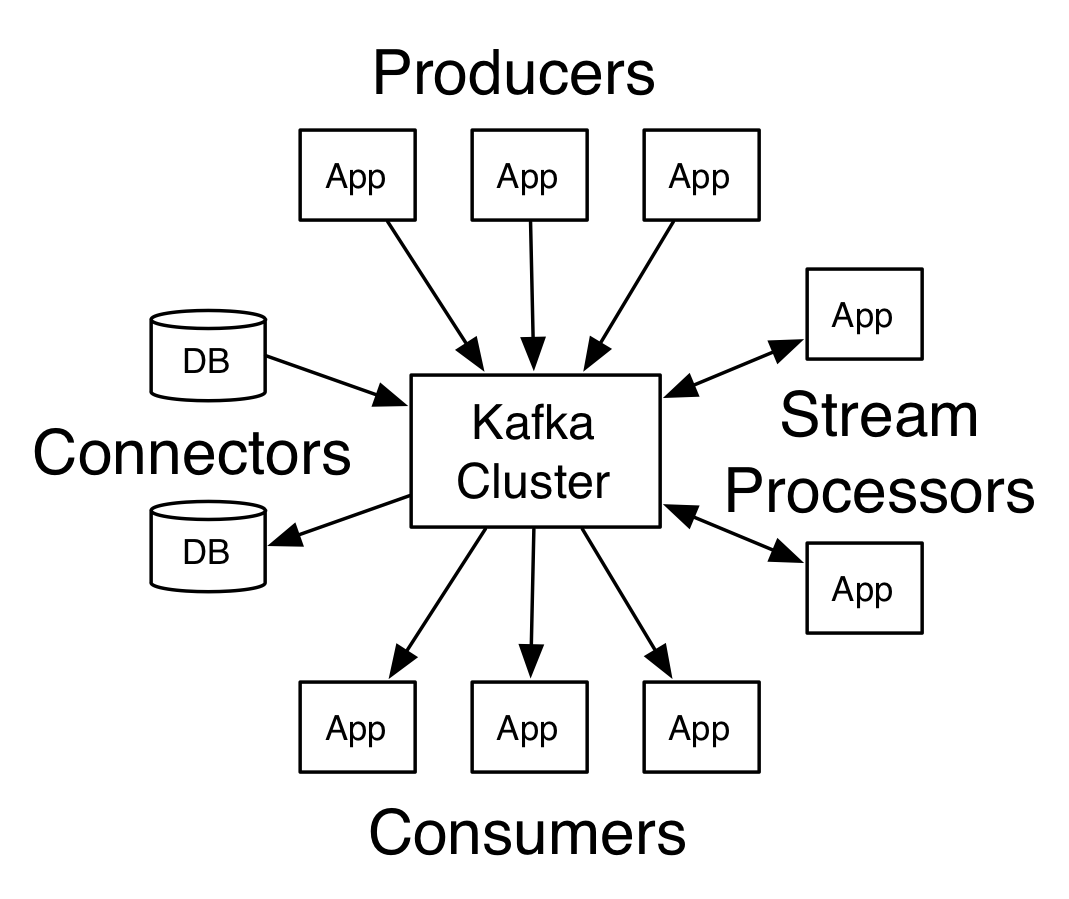
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic .
This protocol is versioned and maintains backwards compatibility with older version.
We provide a Java client for Kafka, but clients are available in .
4.具体的结构
备份属于来源于leader的分区上。
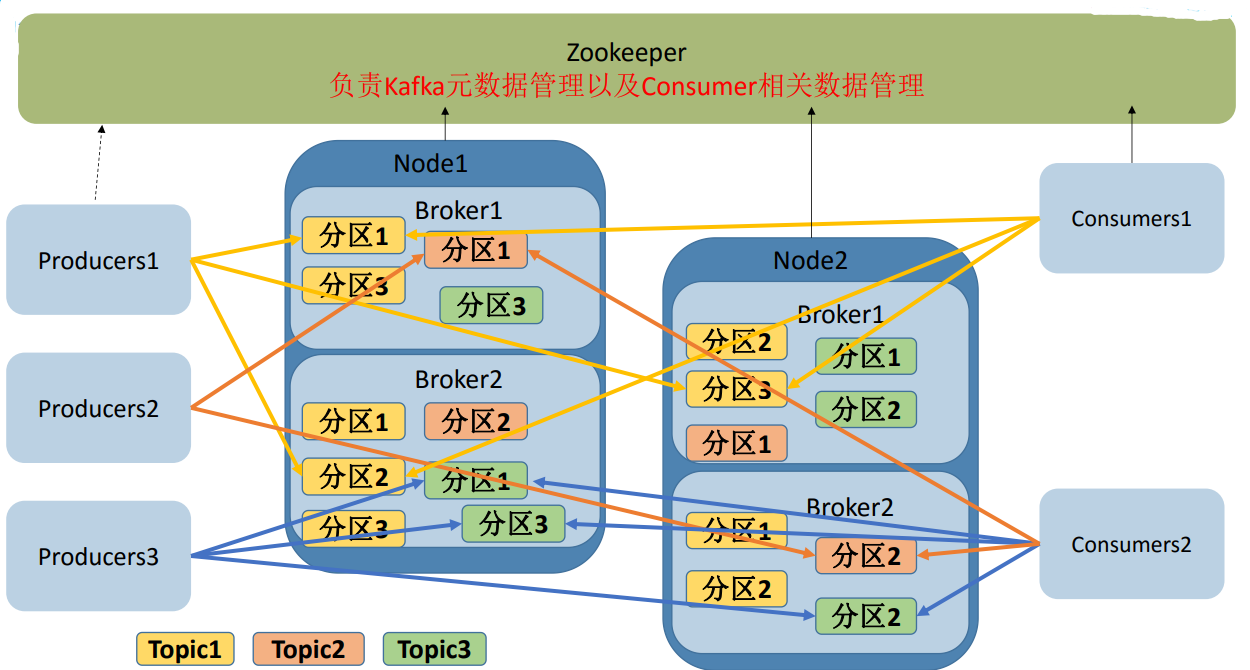
5.术语
重点是Partition。
需要记住的是consumer Group。

6.1.0之后的新特性
这个在上面的图上可以显示出来,官网上的图。

为啥功能这么强大,还要用spark干嘛?
理由是,spark可以转换方便,可以使用SQL。